Data is power, but only if it is collected, processed and managed correctly Eliminate and remedy data duplication!
According to reports, 85% of companies are not effectively leveraging their big data to drive their digital transformation initiatives. While the causes of failure are diverse, from process issues to staffing issues, there is an underlying data quality challenge that is often the root cause of a digital transformation or big data failure. An Experian survey found that 68% of companies experience the impact of poor data quality on their data and transformation initiatives.
Too often, key data quality issues are overlooked until they become a serious bottleneck that causes an initiative to fail. It is only at this point that companies realize that they have been building their data foundations on sand. This article will highlight some of the major problems businesses face and how to rectify them.
The what and why of data quality:
Simply put, data quality refers to the “health” of your data and whether it is fit for its intended use. This means that your data must be:
- Clean and free of errors, such as typos, abbreviations, and punctuation errors.
- Valid and complete in all critical fields, such as phone numbers and email addresses.
- Unique and free of redundancies or duplications
- Accurate and reliable for statistical information, reports and calculations.
- Reliable, updated and accessible whenever necessary.
For most organizations, the data problem only comes to light when a migration or digital transformation initiative is stalled because the data isn’t ready or good enough.
Type of data errors:
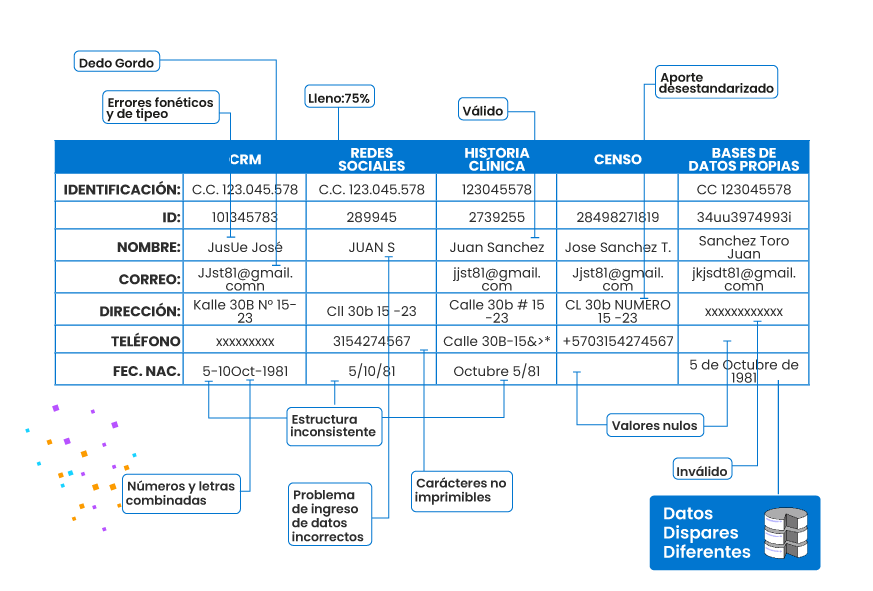
In the case of mergers, it is often the companies that struggle the most with the consequences of poor data. When a company’s customer relationship management (CRM) system breaks, it affects the entire migration process: where time and effort are supposed to be spent understanding and implementing the new system, they are spent! in ordering the data!
What exactly is bad data? Well, if your data presents:
- Human errors, such as misspellings, typos, casing issues, inconsistent naming conventions across the dataset.
- Inconsistent data formatting throughout the dataset, such as phone numbers with and without country code, or numbers with punctuation.
- Invalid or incomplete address data, with missing street names or postal codes
- False names, addresses, or phone numbers
then it is considered to be faulty data, these issues are considered superficial and are unavoidable and universal: as long as there are human beings formulating and entering the data, errors will occur.
However, the poor quality of the data goes beyond superficial problems. If the data is isolated, difficult to access and duplicated, we have serious problems. In fact, data duplication is a key challenge that most organizations find difficult to tackle.

Data Quality Sheet
How can I achieve optimal Data Quality in my company? Learn more about it here, download now for free.
Data duplication and poor data management as the main challenge
On average, companies have about 400 different data sources. Companies are literally drowning in data, especially duplicate data. There are multiple ways to create duplicate data, some of the most common of which are:
A user who enters their details multiple times through different channels: Someone can sign up using multiple emails, causing the number of users to inflate. A company may think they have 10 new signups when in fact they only have three. A user can have multiple names and nicknames. For example, J.C. Sánchez can also be Juan Sánchez or Juan Camilo Sánchez. Mr. Sanchez can enter his name as J.C. Sanchez in a web form, but when he becomes a paying customer and billing information is required, his name may be fully registered in the company’s CRM.
In this particular example, the record of J.C. Sánchez has been duplicated in two different data sources that are also used by two different departments.
Technical or process failures in databases and data sources that may lead to data duplication.
Partial duplications created by human error: When a sales rep or customer service rep enters information manually, for example.
This causes a mismatch even if the records contain the same name or phone number. A spelling error, the difficulty in registering non-Latin names and other similar cases can create duplicates. Partial duplicates are the most difficult to overcome, especially since they are not detected during a normal debugging process.
Data duplication mainly occurs due to lack of data governance and data mismanagement. As organizations grow, they focus simply on collecting data. More leads, more buyers, more sales. Vanity metrics are used to measure success.
If companies actually sorted out their data, they would see a drastic difference between what they think they have and what they actually have.
What exactly is bad data? Well, if your data presents:
- Human errors, such as misspellings, typos, casing issues, inconsistent naming conventions across the dataset.
- Inconsistent data formatting throughout the dataset, such as phone numbers with and without country code, or numbers with punctuation.
- Invalid or incomplete address data, with missing street names or postal codes
- False names, addresses, or phone numbers
then they are considered to be faulty data, these issues are considered superficial and are unavoidable and universal; As long as there are human beings formulating and entering the data, errors will occur.
However, the poor quality of the data goes beyond superficial problems. If the data is isolated, difficult to access and duplicated, we have serious problems. In fact, data duplication is a key challenge that most organizations find difficult to tackle.
Do you need help concretizing that idea? Contact us and you will see how we can help you create, combine and consolidate a 360 Customer View.