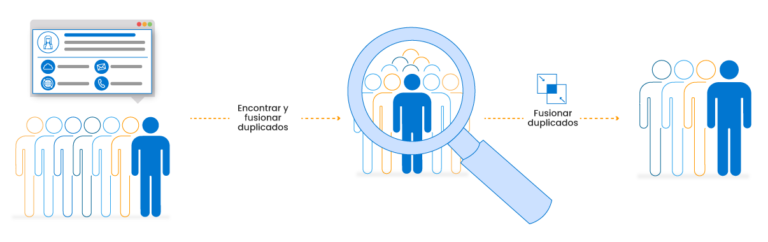
En el mundo actual, impulsado por los datos, las organizaciones lidian con cantidades enormes de información que proviene de diversas fuentes. Esta información, a menudo denominada “datos desordenados”, puede ser inconsistente, propensa a errores y difícil de manejar. Una de las tareas fundamentales en la gestión y el análisis de datos es limpiar y vincular estos datos desordenados para obtener conocimientos significativos. La coincidencia difusa es una técnica poderosa que ayuda a abordar este problema al identificar y conectar puntos de datos similares. En esta guía integral, exploraremos los entresijos de la coincidencia difusa, sus desafíos, soluciones y los beneficios que aporta al mundo del análisis de datos.
¿Qué es la coincidencia difusa?
La coincidencia difusa es una técnica de limpieza y vinculación de datos que le permite comparar y conectar puntos de datos que no son coincidencias exactas, pero que son lo suficientemente cercanos como para considerarse relacionados. Es especialmente útil al tratar con datos que pueden contener errores tipográficos, errores ortográficos, abreviaturas u otras discrepancias. Los métodos de coincidencia exacta tradicionales fallan en tales casos, lo que convierte a la coincidencia difusa en una herramienta indispensable para los profesionales de datos.
Los desafíos de los datos desordenados
Antes de adentrarnos en las complejidades de la coincidencia difusa, es esencial comprender los desafíos que plantean los datos desordenados:
- Variabilidad: Los datos pueden variar significativamente debido a diferentes prácticas de entrada de datos, convenciones de nomenclatura inconsistentes y errores humanos. Por ejemplo, el mismo nombre puede representarse como “John Smith”, “J. Smith” o “Smith, John”.
- Errores tipográficos y ortográficos: Errores tipográficos o errores ortográficos simples pueden dificultar la coincidencia de registros similares. “Jonh” y “John” pueden representar la misma entidad, pero no son coincidencias exactas.
- Abreviaturas y acrónimos: Diferentes variaciones de la misma entidad pueden escribirse como acrónimos, abreviaturas o nombres completos, lo que dificulta aún más la coincidencia. Por ejemplo, “NASA” y “National Aeronautics and Space Administration”.
- Errores en la entrada de datos: Los errores humanos en la entrada de datos pueden introducir inconsistencias. Un error de un solo dígito en un número de teléfono o código postal puede dificultar la coincidencia.
- Datos incompletos: Datos incompletos o parcialmente faltantes pueden dificultar la coincidencia precisa de registros. Por ejemplo, intentar vincular individuos solo con sus nombres y direcciones parciales.

Lo básico de la coincidencia difusa
La coincidencia difusa funciona asignando una puntuación de similitud a pares de puntos de datos, lo que indica qué tan cerca se ajustan. Se utilizan varios algoritmos y técnicas para este propósito, siendo algunos de los más comunes:
- Distancia de Levenshtein (Distancia de edición): Este algoritmo calcula el número mínimo de ediciones de un solo carácter (inserciones, eliminaciones o sustituciones) necesarias para transformar una cadena en otra. Cuanto menor sea la distancia, mayor será la similitud.
- Similitud de Jaccard: Este método se utiliza principalmente para comparar conjuntos de elementos. Calcula la similitud entre dos conjuntos dividiendo el tamaño de su intersección por el tamaño de su unión.
- Similitud del coseno: La similitud del coseno mide el coseno del ángulo entre dos vectores no nulos en un espacio n-dimensional. A menudo se utiliza en análisis de texto y procesamiento de lenguaje natural.
- Soundex: Este algoritmo fonético codifica palabras en una representación simplificada basada en su pronunciación, lo que lo hace útil para emparejar nombres con sonidos similares.
La coincidencia difusa en acción
Ilustremos el poder de la coincidencia difusa con un ejemplo práctico. Consideremos un conjunto de datos con nombres y direcciones de clientes. Debido a errores humanos e inconsistencias en la entrada de datos, el mismo cliente puede estar representado de varias maneras. Así es cómo la coincidencia difusa puede ayudar:
Coincidencia exacta: Si intentáramos vincular registros utilizando la coincidencia exacta, “John Smith” y “John Smtih” no serían considerados una coincidencia, lo que haría que datos valiosos no se vincularan.
Coincidencia difusa: Por otro lado, la coincidencia difusa reconocería la similitud entre “John Smith” y “John Smtih” al calcular una distancia de Levenshtein de 1 (solo una diferencia de carácter). Esto permite la vinculación correcta de estos registros.
Superar los desafíos de la coincidencia difusa
Aunque la coincidencia difusa es una técnica poderosa, presenta su propio conjunto de desafíos. Aquí hay algunos problemas comunes y sus soluciones:
- Escalabilidad: La coincidencia difusa puede ser computacionalmente costosa, especialmente al tratar con conjuntos de datos grandes. Para superar este desafío, considere el procesamiento paralelo o la informática distribuida.
- Selección del umbral: Elegir un umbral de similitud apropiado es crucial. Un umbral más bajo puede resultar en falsos positivos, mientras que uno más alto podría dar lugar a falsos negativos. Las técnicas de validación cruzada pueden ayudar a determinar el umbral óptimo.
- Manejo de datos multilingües: La coincidencia difusa puede volverse más compleja al trabajar con datos multilingües. Existen bibliotecas y algoritmos especializados para abordar este problema.
- Preprocesamiento de datos: El preprocesamiento de datos eficaz es vital. Esto incluye la estandarización del texto, la conversión a minúsculas, la eliminación de caracteres especiales y el manejo de datos faltantes.
- Ajuste de algoritmos: Dependiendo del tipo de datos con el que esté trabajando, puede ser necesario ajustar el algoritmo de coincidencia difusa. Por ejemplo, el uso de algoritmos fonéticos para nombres y la distancia de edición para direcciones.
Los beneficios de la coincidencia difusa
La coincidencia difusa ofrece una gran cantidad de beneficios, lo que la convierte en una herramienta valiosa para los profesionales de datos:
- Mejora de la calidad de los datos: Al conectar puntos de datos relacionados, la coincidencia difusa mejora la calidad general de su conjunto de datos, reduciendo inexactitudes y redundancias.
- Mejora de la integración de datos: La coincidencia difusa permite la integración de datos de diversas fuentes, incluso cuando esas fuentes utilizan diferentes formatos o convenciones de nomenclatura.
- Análisis mejorado de datos: Los datos limpios y vinculados proporcionan una base más precisa para el análisis de datos, lo que conduce a información más confiable y significativa.
- Reducción del esfuerzo manual: La coincidencia difusa automatiza el proceso de limpieza y vinculación de datos, ahorrando tiempo y recursos a las organizaciones.
- Mejora de las relaciones con los clientes: En bases de datos de clientes, la coincidencia difusa garantiza que los clientes se identifiquen con precisión, lo que mejora el servicio al cliente y los esfuerzos de marketing.
- Deduplicación eficaz de registros: La coincidencia difusa es indispensable para la deduplicación de registros en bases de datos, lo que conduce a una gestión de datos más limpia y eficiente.
Casos de uso de la coincidencia difusa
La coincidencia difusa se aplica en diversos campos, incluyendo:
- Gestión de relaciones con el cliente (CRM): Para consolidar y limpiar registros de clientes en esfuerzos de marketing y ventas.
- Salud: Para la coincidencia de pacientes y la consolidación de registros médicos.
- Comercio electrónico: Para agrupar productos similares y gestionar el inventario de manera efectiva.
- Servicios financieros: Para la detección de fraudes y la evaluación de riesgos mediante la vinculación de transacciones relacionadas.
- Análisis de texto: Para identificar documentos o contenido similares en tareas de procesamiento de lenguaje natural.
- Genealogía: Para emparejar nombres y relaciones en bases de datos genealógicas.
Conclusión
En el mundo de la gestión de datos, tratar con datos desordenados es una realidad, y la coincidencia difusa es una herramienta poderosa para limpiar y vincular estos datos. Permite a las organizaciones desbloquear todo el potencial de sus datos al reducir errores, mejorar la calidad de los datos y permitir un análisis más preciso.
Si bien la coincidencia difusa presenta sus propios desafíos, comprenderla e implementarla de manera efectiva puede brindar beneficios significativos. Automatiza el proceso de limpieza y vinculación de datos, reduce el esfuerzo manual y mejora la integración de datos, lo que en última instancia conduce a una toma de decisiones más acertada y a una mejor relación con los clientes. La coincidencia difusa es una habilidad valiosa para los profesionales de datos, que ofrece una sólida solución para uno de los desafíos más comunes en el mundo impulsado por los datos.
Para más información (externa): https://techinfo.wiki/coincidencia-difusa/
Te deseamos mucho éxito y no te pierdas nuestros útiles consejos sobre la coincidencia difusa que estaremos subiendo a nuestro canal de youtube https://www.youtube.com/@DatosMaestrosLATAM ¡Esperamos poder ayudarte a alcanzar tus metas con la coincidencia difusa con nuestros servicios y combinado con CUBO iQ® PlataForma de auditoria de calidad de datos con un enfoque no invasivo a la limpieza y vinculación de datos revolucionaria! ???
También puedes comunicarte con nosotros si tienes preguntas relacionadas con este documento o si deseas discutir sobre tu iniciativa de la coincidencia difusa y limpieza y vinculación de datos revolucionaria. Escríbenos a contacto@datosmaestros.com o agenda aqui sin compromiso.
![]()