Introducción
En el mundo actual impulsado por los datos, las organizaciones generan y gestionan grandes cantidades de datos. Desde registros de clientes hasta información de productos y transacciones financieras, los datos son el motor de las empresas modernas. Sin embargo, con la proliferación de datos surge un desafío significativo: los datos duplicados. Los datos duplicados pueden provocar ineficiencias, costos de almacenamiento elevados y análisis inexactos. Para combatir este problema, las organizaciones recurren a la deduplicación de datos. En esta guía completa, exploraremos las prácticas de deduplicación de datos, los desafíos y su importancia en el panorama de gestión de datos.
¿Qué es la Deduplicación de Datos?
Definición
La deduplicación de datos, a menudo simplemente denominada deduplicación, es una técnica de reducción de datos que elimina copias duplicadas de datos. Garantiza que solo se retenga una única instancia de un conjunto de datos, mientras que las copias redundantes se eliminan.
Cómo Funciona la Deduplicación de Datos
La deduplicación de datos opera a nivel de bloques o archivos. Cuando se ingresa datos, se divide en segmentos pequeños, comúnmente denominados “trozos” o “bloques”. Los algoritmos de eliminación de duplicados analizan estos fragmentos e identifican duplicados según su contenido. Cuando se detecta un duplicado, solo se almacena una copia, y las referencias posteriores a esos datos apuntan a la copia existente. Este proceso reduce significativamente los requisitos de almacenamiento de datos.
La Importancia de la Deduplicación de Datos
Uso Eficiente de los Recursos de Almacenamiento
Una de las principales ventajas de la deduplicación de datos es el uso eficiente de los recursos de almacenamiento. Al eliminar datos redundantes, las organizaciones pueden almacenar más datos en menos espacio físico. Esto resulta en ahorros de costos y reduce la necesidad de infraestructura de almacenamiento adicional.
Copias de Seguridad y Recuperación Más Rápidas
La deduplicación de datos acelera los procesos de copia de seguridad y recuperación. Dado que solo se respalda información única, el proceso es más rápido y consume menos recursos de red y almacenamiento. En caso de pérdida de datos o recuperación ante desastres, la restauración de datos a partir de copias de seguridad deduplicadas es más rápida y eficiente.
Mejora de la Calidad de Datos
Los datos duplicados pueden generar inconsistencias y errores en informes y análisis. La deduplicación de datos contribuye a mantener la calidad de los datos al garantizar que solo se retenga información precisa y actualizada. Esto, a su vez, mejora la toma de decisiones y la inteligencia empresarial.

Prácticas de Deduplicación de Datos
1. Identificar Fuentes de Datos Duplicados
Antes de implementar la deduplicación de datos, las organizaciones deben identificar las fuentes de datos duplicados. Esto incluye bases de datos, servidores de archivos, sistemas de correo electrónico y cualquier otro repositorio donde se almacenen datos. Comprender de dónde provienen los duplicados es fundamental para diseñar una estrategia efectiva de deduplicación.
2. Elegir el Método de Deduplicación Correcto
Existen varios métodos de deduplicación de datos, que incluyen:
a. Deduplicación en Línea La deduplicación en línea identifica y elimina duplicados a medida que los datos se ingresan en el sistema de almacenamiento. Requiere más potencia de procesamiento, pero ofrece beneficios de eliminación de duplicados en tiempo real.
b. Deduplicación Post-Procesamiento La deduplicación post-procesamiento ocurre después de que los datos se almacenan. Involucra escaneos periódicos del repositorio de datos para identificar y eliminar duplicados. Este método requiere menos recursos, pero puede no ofrecer los beneficios de eliminación de duplicados en tiempo real.
c. Deduplicación en el Lado de Origen La deduplicación en el lado de origen se realiza en la fuente de datos, como en dispositivos cliente antes de que los datos se transmitan al sistema de almacenamiento. Esta aproximación reduce el consumo de ancho de banda de red.
d. Deduplicación en el Lado de Destino La deduplicación en el lado de destino se lleva a cabo en el objetivo de almacenamiento, como un dispositivo de copia de seguridad o una matriz de almacenamiento. A menudo se utiliza en situaciones de copia de seguridad y recuperación ante desastres.
3. Implementar Software o Dispositivos de Deduplicación de Datos
Para llevar a cabo la deduplicación de datos de manera efectiva, las organizaciones pueden utilizar soluciones de software dedicadas o dispositivos diseñados para este propósito. Soluciones populares de eliminación de duplicados incluyen Veritas NetBackup, Dell EMC Data Domain y Veeam Backup & Replication.
4. Supervisar y Optimizar las Políticas de Deduplicación
Una vez implementada la deduplicación de datos, es esencial supervisar y optimizar continuamente las políticas de deduplicación. Esto garantiza que el proceso de eliminación de duplicados siga siendo efectivo a medida que los datos evolucionan con el tiempo.

Desafíos de la Deduplicación de Datos
Aunque la deduplicación de datos ofrece numerosos beneficios, también conlleva sus propios desafíos:
1.Sobrecarga de Procesamiento La deduplicación de datos requiere una potencia de procesamiento significativa y recursos de memoria. Esto puede generar costos de hardware más elevados, especialmente en la deduplicación en línea.
2.Fragmentación de Datos La deduplicación divide los datos en fragmentos más pequeños para su análisis, lo que puede dar lugar a la fragmentación de datos. La reasambleción de datos durante la recuperación puede introducir latencia.
3.Deduplicación en Múltiples Ubicaciones Las organizaciones con datos distribuidos en múltiples ubicaciones pueden enfrentar desafíos para deduplicar datos de manera eficiente a través de la red.
4.Deduplicación Inicial de Datos Realizar el proceso inicial de eliminación de duplicados en una gran cantidad de datos existentes puede ser demorado y requerir muchos recursos.
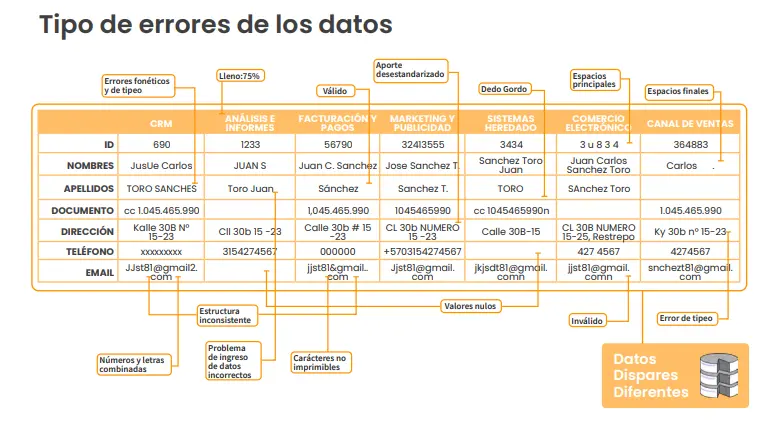
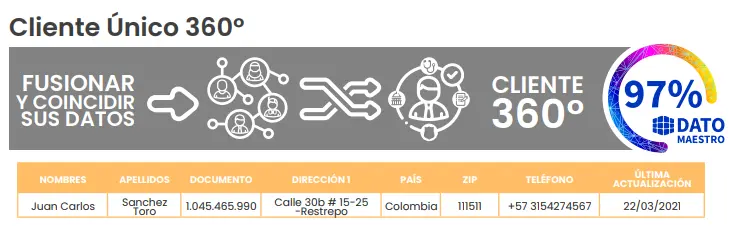
Técnicas Avanzadas de Deduplicación de Datos
1. Segmentación Variable
Las técnicas tradicionales de deduplicación de datos utilizan segmentos de tamaño fijo para identificar duplicados. Sin embargo, la segmentación variable permite una deduplicación más eficiente al dividir los datos en segmentos de tamaño variable según patrones de contenido. Este enfoque puede mejorar las tasas de eliminación de duplicados, especialmente para conjuntos de datos con patrones de datos irregulares o no uniformes.
2. Deduplicación de Datos de Diversos Tipos
Las soluciones modernas de deduplicación de datos pueden manejar diversos tipos de datos, incluidos datos estructurados y no estructurados, bases de datos, correos electrónicos y archivos multimedia. La deduplicación de datos en varios tipos de información plantea desafíos adicionales, pero ofrece beneficios significativos en términos de optimización de almacenamiento.
3. Deduplicación Global
La deduplicación global extiende las capacidades de eliminación de duplicados a través de múltiples ubicaciones o centros de datos. Asegura que los duplicados se eliminen de manera consistente en toda la infraestructura de la organización, proporcionando un enfoque unificado para la gestión de datos.
Aplicaciones del Mundo Real de la Deduplicación de Datos
1. Copias de Seguridad y Recuperación de Desastres
La deduplicación de datos desempeña un papel crucial en las soluciones de copias de seguridad y recuperación de desastres. Al eliminar copias redundantes de respaldos, las organizaciones pueden reducir los costos de almacenamiento y acelerar la recuperación de datos en caso de pérdida de información o desastres.
2. Virtualización
Las tecnologías de virtualización a menudo generan datos duplicados debido al uso de plantillas y instantáneas. La deduplicación de datos en entornos virtualizados ayuda a optimizar la utilización del almacenamiento y mejorar el rendimiento.
3. Almacenamiento en la Nube
Los proveedores de almacenamiento en la nube emplean la deduplicación de datos para minimizar el costo de almacenar y transmitir datos. La eliminación de duplicados permite un uso eficiente de los recursos en la nube y reduce los requisitos de ancho de banda para la transferencia de datos.
4. Sistemas de Correo Electrónico
Los servidores de correo electrónico pueden acumular grandes cantidades de correos electrónicos y archivos adjuntos duplicados. La implementación de la deduplicación de datos en sistemas de correo electrónico ayuda a reducir la sobrecarga de almacenamiento y simplifica el archivo de correos electrónicos.
Tendencias Emergentes en la Deduplicación de Datos
1. Aceleración de la Deduplicación en Línea
Los avances en hardware, como aceleradores de hardware dedicados y tarjetas FPGA (Field-Programmable Gate Array), están haciendo que la deduplicación en línea sea más rápida y eficiente. Esto permite que las organizaciones logren la eliminación de duplicados en tiempo real sin una sobrecarga significativa de procesamiento.
2. Integración de Aprendizaje Automático
Los algoritmos de aprendizaje automático se están integrando en soluciones de deduplicación de datos para mejorar la precisión de la deduplicación. Estos algoritmos pueden identificar patrones duplicados de manera más efectiva, incluso en casos donde los datos están oscurecidos o cifrados.
3. Deduplicación de Datos en la Informática en el Borde
Con la proliferación de dispositivos de informática en el borde y sensores de IoT (Internet de las cosas), la deduplicación de datos se vuelve esencial en el borde. La eliminación de duplicados en el borde reduce los requisitos de transferencia y almacenamiento de datos, lo que hace que la informática en el borde sea más eficiente y rentable.
4. Deduplicación de Datos como Servicio
Algunos proveedores de la nube ofrecen la Deduplicación de Datos como Servicio (DDaaS). Esto permite que las organizaciones externalicen las complejidades de la eliminación de duplicados a la nube, reduciendo la necesidad de hardware y gestión en las instalaciones.
Para más información: https://www.grupocomunicar.com/wp/escuela-de-autores/duplicidad-de-la-informacion/
Conclusión
La deduplicación de datos es un componente crítico de las estrategias modernas de gestión de datos. Aborda los desafíos planteados por los datos duplicados al eliminar eficientemente copias redundantes, lo que optimiza el almacenamiento, mejora la calidad de los datos y aumenta la velocidad de procesamiento de la información.
Técnicas avanzadas, aplicaciones del mundo real y tendencias emergentes continúan dando forma al panorama de la deduplicación de datos, convirtiéndola en una herramienta en constante evolución e indispensable para las empresas que buscan aprovechar todo el potencial de sus recursos de datos. A medida que las organizaciones continúan lidiando con el creciente volumen de datos, la eliminación de duplicados de datos seguirá siendo un elemento clave en su búsqueda de eficiencia y competitividad en la era digital.
¿Ya descargaste CUBO iQ® Gratis de Por Vida? Que esperas descarga aqui